
What is the New AI? Part 2: From the Inside

This post picks up where What Is the New AI? Part 1: From the Outside left off. That article introduced AI for Mortals and its purpose: to give regular, non-technical people the tools to think about the new (generative) AI for themselves. It reviewed the way ChatGPT and similar programs captured the world’s attention in 2023, and explored the capabilities that make this new type of AI so very different from anything that’s gone before.
If you haven’t read that story, please consider starting there.
In this post, we’ll look at what’s inside programs like ChatGPT: the things that make their astonishing external behaviors possible. Fear not! Even though this will be slightly more technical than the average AI for Mortals post, it’s going to be easy and fun. Strange as it may seem, the things mortals really need to understand are simple and accessible. (With one caveat — a big one. We’ll get to it.) If you do get hung up on anything, just skim on through. The overall story is more important than the details.
As in Part 1, we’re still focusing on what the new AI is, as opposed to what it means. AI’s meaning — its promises and perils — will come to be our main subject in future posts, but first we have to understand what we’re talking about. Onward!
What are we looking for?
If you were setting out to build a world-class new AI system for research or industry, you’d need serious expertise in a lot of crazy stuff.

Okay, I confess. According to the photo site where I found him, this guy is a “funny botanist”. But…close enough! I can tell by the copious signs of wizardly know-how, the nerd-chic spectacles, and the general attitude of delighted bewilderment that he’d make a crack computer scientist.
Then he’d have to worry about a whole lot of theoretical and practical minutiae that you, dear mortal, are free to ignore. I’m going to make it simple for you without losing the crucial concepts you need to make sense of sharing the planet — and the cosmos — with the new AI. By the time we’re done, you’ll understand the most important things better than a lot of professional programmers and tech journalists.
What are we looking for? Well, recall from Part 1 that the new AI exhibits extreme leaps in multiple areas of performance that take it far beyond what legacy software can do: talking to you for real in your own language, “sparks of intelligence”, as a Microsoft research paper put it, and internalized knowledge of large swaths of humanity’s cultures and values.
We’re looking inside the new AI to find the secret sauce that allows it, seemingly out of nowhere, to accomplish such feats.
What if there is no secret sauce?
Conditioned perhaps by the extreme rates of change that have been normal in tech for decades, some people assume this is just more of the same.
“It’s all just code”, “They can only do what they’re programmed to do”, “It’s only pattern matching”, “We’ve been through paradigm shifts before”: all these and more are ways to say that amazing as some of the results may be, this is incremental change. The secret sauce, according to these people, is nothing.
Here’s industry titan and AI super-booster Marc Andreessen:
AI is a computer program like any other — it runs, takes input, processes, and generates output…It is owned by people and controlled by people, like any other technology.
AI critics sometimes say comparable things, though they use different words and emphasize different points. If you’ve seen ChatGPT-style AIs referred to (here in a 2021 paper by Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Margaret Mitchell) as “stochastic parrots”, that’s cynic-speak for “all they can do is stupid pattern-matching”.
Similarly, Parmy Olson, in a March 2023 Washington Post article, simply says There’s No Such Thing as Artificial Intelligence (unlocked link). She asserts that the very name AI breeds misunderstanding, and looks for a different term, evaluating several alternatives before concluding:
The most hopeless attempt at a semantic alternative is probably the most accurate: “software.”
Thus, among both the boosters and the skeptics, there are genuine experts (though a minority, I think, in both cases) who agree: there is no secret sauce; it’s just software.
This is a critical question, because if the new AI is really just software, then we are firmly within the realm of the known. Whether you’re more in Mr. Andreessen’s camp or that of Ms. Olson, you can stick to the playbook you’re already using, whether that means celebrating or decrying the status quo.
Is this true, though? Is the new AI just software? I don’t think so, but let’s take a look, and then, like a good responsible mortal, you can judge for yourself.
Large Language Models
New AI chatbots like ChatGPT are based on large language models, or LLMs.
An LLM is usually described for general audiences as a model where you feed in a chunk of text, and the LLM predicts the word most likely to come next. An application program, such as a chatbot, calls the LLM repeatedly, getting one predicted word at a time, adding it to the end of its current text, and feeding the result back through the LLM to get the next word.
(This description, and what I go on to say below, take some liberties with the details. I promise this doesn’t matter for our purposes, but if you’re curious, there’s a section at the end of this post where I come clean about the most important points.)
Let’s look at an example. I give GPT-4 the following prompt:
At the top of the sign is the word WARNING in big red letters. You have to move closer to read the two following lines. They say
and it responds:
“Slippery When Wet” and “Proceed With Caigo”.
(Yeah, “Caigo”. Don’t look at me — that’s what it said!) What happens under the covers? The chat application sends my prompt to the LLM, which replies like so:
“Slippery
The chat program adds that word to what it’s got so far, and feeds it through again. It’s just the same as before, except that now it has that one new word added at the end:
At the top of the sign is the word WARNING in big red letters. You have to move closer to read the two following lines. They say “Slippery
This time the LLM responds with:
When
Now the chat app adds that word to the text, and sends it back through the LLM again, this time receiving in reply the word Wet. And so on, until at some point the LLM returns a special end token to signal that the most likely thing to follow the current text is nothing. That’s when the chat program considers the response complete.
So you can see that if we’re going to find any secret sauce, the LLM is where we’re going to find it, because that’s where the action is happening, one word at a time.
LLMs are neural networks
No, no wait! Come back! You’re going to understand this whole thing in just a few minutes, I promise. We only need a couple more things to get to the big insight part.
Artificial neural networks — or in this context, just neural networks — are one of several ways to build AI. They go back all the way to — get ready — the 1950s! (And their theoretical underpinnings, without even the benefit of machines able to execute them, were being worked out even way earlier that that.) Neural networks have competed for attention with other AI architectures over time, but right now, they’re the ones getting most of the glory.
LLMs — large language models, like the one ChatGPT uses—are one particular kind of neural network. They arrived on the scene in 2018; see the bottom of this post if you’re interested in a brief recap of how that happened.
Neurons and networks
Here’s a generic illustration of a biological neuron, typical of ones in your nervous system, including your brain:
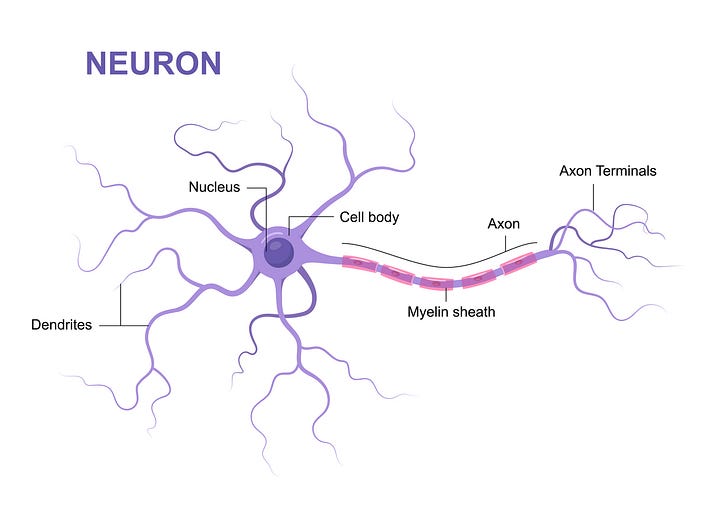
Signals arrive from other neurons at the dendrites, get processed in the cell, and sometimes activate output signals through the axon. To a first approximation, your brain is a network of such neurons connected by the dendrites and axons.
Artificial neural networks do a much simplified version of the same thing. In typical cases, including LLMs, individual neurons and their connections don’t grow and change over time as they do in biological networks. Each LLM neuron takes a fixed number of inputs and produces a single output, and the neurons are arranged in layers that are fixed from the beginning. Input — like your prompt — comes in at the first layer, and final output emerges from the last layer. It all looks something like this:
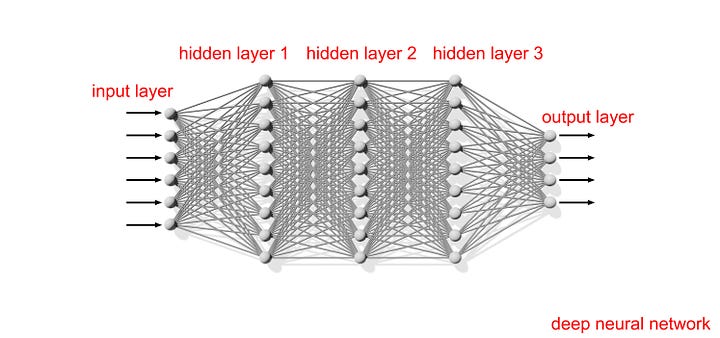
As you can see, the structure of the network is a simple thing. It’s just a lattice, arranged in layers. In LLMs (and many, but not all, other types of neural networks) each neuron’s output goes to every neuron in the next layer. Nothing about the structure reflects anything about the real world, and it never changes.
The individual neurons are simple things too. They don’t contain any inherent significance, or any programming.
The only things a neuron contains are:
- A weight for each of its incoming connections. This is just a number that says how much influence that particular input should have when the neuron computes an output. When the LLM is built, the weights are set to random numbers. They’re adjusted during the training process, but after that, they don’t change further.
- A simple, fixed rule for how the inputs are combined to produce an output. (Not only are these rules simple and fixed, there are usually only two in the entire network: one used by all the neurons in the output layer, and another used by all the rest.)
That’s it!
Where do we put the secret sauce?
What we’ve been talking about is called the architecture of the neural network, but it’s a very strange type of architecture.
In the architecture of a house, everything is about the purposes of the house: the bedroom is set up for sleeping, the kitchen is designed for cooking, and so on. The kitchen, bathrooms, and laundry are clustered around pathways where the plumbing can run, and that helps each of these rooms serve its purpose.
In the architecture of a conventional software program, everything is organized around the purposes of the program: this module is designed to retrieve your account records, that module is designed to show you the latest offers, and this other module is designed to take your money if you decide to buy something.
The LLM’s neural network architecture isn’t like that. Nothing in it is about anything.
If you could peer inside the untrained model, you wouldn’t see anything to indicate it was meant to do language prediction. (In fact, at this stage, you really could train it to do something else!)
It’s just a blank and meaningless array of neurons, which are themselves blank and meaningless.
It’s like taking the red pill and finding yourself staring into the reality of the Matrix, except that if you were newly-pilled Neo, at least you’d be looking at the nutrient vats, and at least they’d make sense on their own terms: here’s the chamber where we keep the poor humans confined, here’s where the nutrients flow in, here’s where the power is conducted out.
As built, our neural network doesn’t even have a reality layer like that. It’s just…blank. Nothing in it means anything.
Q. If the network structure is trivial, and the neurons don’t contain any programming, and the weights are random, and the summation and activation rules are simple and fixed, how do the LLM’s builders put any behavior of any kind into it, let alone the crazy stuff that makes people think ChatGPT is going to revolutionize the world?
A. They don’t. There’s nowhere they can put anything, just like you said.
Now, take a look back at how I described the parts of the architecture. Do you see the answer to this conundrum?
There’s one and only one place any magic can slip in, or any meaningful structure or behavior at all. It’s in the training of the weights, the numbers that determine the strength of each neuron-to-neuron connection. After the network is built, but before the weights are locked in for the LLM’s release, the training process constructs every single bit of what makes the model work.
Training the weights
Human beings are not involved in training the model’s weights, not directly. They do create the LLM’s training corpus by collecting internet text, book databases, research papers, and so on, and they do specify the training algorithm. (There’s rightfully a lot of contention around the way training data is collected and used. Future posts in AI for Mortals will talk about this a lot, but right now we’re just trying to understand how it all works.) And humans do fine-tune the model’s behavior in several ways after it’s built.
But the initial training of the weights is conducted by the model itself in a process called self-supervised learning. This is basically a dialogue between the model and the training data. For example, in an early stage of training, when the weights are still nearly random, one of the tiny steps might be for the model to look at A Tale of Two Cities, asking itself, “Okay, self, what comes after “It was the best of times, it was the worst of”? Metaphorically covering the answer with its hand, it would then grind away to come up with a prediction. Since its weights are nearly random at this early stage of training, it would come up with something that’s also nearly random, maybe “chocolate”. Lifting its hand to reveal the answer…bzzzt. It was supposed to be “times” — the model can see this, because the actual text of the book is in the training set. So it applies some fancy math to decide which way to adjust the weights, and moves its training forward one little step.
Gradually and automatically, as training proceeds, the pressure to make accurate predictions forces the weights and neurons throughout the network to absorb meaning from the training set.
The wall
After a lot of training — Kasper Groes Albin Ludvigsen has estimated GPT-4’s initial training to have taken 90 to 100 days of continuous processing on 3,125 heavy-duty graphics servers — the LLM’s array of weights is ready, and the model can be deployed.
Now the model makes real-world sense. It’s impossible to think about at the scale of an LLM, but suppose we have a tiny model, with just a handful of neurons, that estimates house prices for a toy version of Zillow. Suppose we look inside this model. Maybe we find a neuron with large weights on inputs (from neurons in the prior layer) that have to do with schools nearby, distance to transit, neighborhood attractions, and so on. It’s the location, location, location neuron! Then, because this neuron’s output becomes an input to neurons at the next layer, we could — theoretically — figure out which of those neurons have heavy weights on location.
Why do I say theoretically? Because the analysis is impossible to perform for models of practical size, let alone ones as massive as LLMs. There’s nothing that tells us what role a particular weight or neuron plays in the trained system; that can only be guessed at by tracing the behavior of the system with specific examples. (Notice that even in our toy example, we played a little fast and loose by assuming we knew in advance what the subject neuron’s inputs meant. In real life, that wouldn’t be the case!) What’s worse, tidy, single-purpose neurons like our hypothetical location neuron seem to be rare. Most of the time, it’s not crisply organized: the logic is in there, but the training process smears it all over the place.
In general, the weights are inscrutable, and there are a lot of them. They’re not really a two-dimensional array, but remembering how simple and non-meaningful the LLM’s network structure is, it does no harm to think of them as an immense wall of numbers. (The very latest models as of this writing, such as GPT-4 and Google’s Gemini Ultra, complicate this picture a bit by combining more than one LLM into a single system, but the principle holds.)
These numbers, the weights, are what you may have seen referenced as parameters in articles about the relative sizes of models: for instance, GPT-3 is a 175 billion parameter model, GPT-4 is a collection of eight 220 billion parameter models, Gemini Ultra is…well, we don’t know, but it’s probably even bigger.
What if you printed out a 220 billion parameter model’s wall of weights? With a typewriter font and some reasonable assumptions, here’s what it would look like: two kilometers tall and eleven kilometers wide. I added the Eiffel Tower for scale. Sorry if you can’t read the individual weights; they’re…kind of tiny at this scale!

If you’re viewing the above image at native resolution, each pixel represents a square about ten meters on a side.
Picture a single piece of letter-size paper crammed full of compactly displayed numbers. You’ll need something like 1600 such packed sheets to fill your single pixel. Now extend that to the entire wall. 220 billion is a big number.
Remember that each of these numbers, the weights, is just the strength of one connection between two neurons in the network. At the beginning of training, the connection and both the connected neurons are meaningless. Training puts the meaning in, and it’s all in the form of these weights. Don’t worry if you can’t wrap your head around this. Nobody can. It just is.
The insight
Okay, phew! Now you have everything you need for the big insight about what’s going on inside ChatGPT, or any large language model (and, as mentioned at the top of this post, the big caveat that goes with it).
Let’s think about the wall in connection with this dialogue shared by my friend, writer Dee Axelrod. She got this on one try using the free version of ChatGPT:
Dee’s prompt:
In the style of James Joyce’s “Ulysses,” Molly’s soliloquy, describe doing the dishes.
And now ChatGPT’s response:
Sure, attempting to capture the stream-of-consciousness style reminiscent of James Joyce’s “Ulysses,” here’s a portrayal of doing the dishes in a Molly Bloom-esque soliloquy:
Water rushing, a cascade of liquid chatter, clattering plates, and the chime of cutlery — mundane symphony, the wash basin, a baptismal font for culinary transgressions, where fragments of meals past converge. Suds swirl, dance, embrace the remnants of the day’s feasting, the residue of life’s little indulgences. Soap, a fragrant oracle, an alchemical elixir that transforms the profane into the immaculate.
Hands immersed in the frothy abyss, fingers probing the murky depths, caressing the detritus of sustenance. Ceramic and metal, vessels of memory, bearing witness to the epicurean saga enacted upon their surfaces. A sonnet of grease and grime, a sestina of saucepans — each pot and pan, a protagonist in the grand narrative of nourishment.
Thoughts flutter like soap bubbles, ephemeral and iridescent — fragments of the day’s musings and memories mingling with the remnants of meals. The rhythmic scrubbing, a metronome marking time in the symphony of domesticity. Dishes, like characters in a novel, emerge cleansed, ready for the next culinary odyssey.
The kitchen, a sanctuary of domestic sacrament, where the ritual of dishwashing becomes a meditative prose poem, an exhalation of the day’s chaotic inhalation. And as the final glass gleams, reflecting the ambient glow of the overhead light, a sense of accomplishment settles — a quiet denouement to the culinary opera that unfolds daily, in the heart of the home.
So. ChatGPT has moved its narrative style a little, though only a little, in the direction of Joyce’s soliloquy. On the other hand, it has created a genuinely beautiful passage that demonstrates a thorough understanding of the process of dishwashing, and also includes a much more superficial account of the dishwasher. It’s full of apt, concrete description. It makes numerous references to the place dishwashing occupies in the context of the daily life of a household, in some cases making connections that approach the profound. It’s wonderfully lyrical.
Now, this is the LLM at its most impressive. This “do X in Y style” type of request plays to its strengths. Even then, if you offer the same prompt repeatedly, you’ll find that its responses are somewhat stereotyped. A different model might not respond as well (or might respond better. Interestingly, GPT-4 doesn’t respond quite as well to this particular prompt.) And the response here didn’t include any flat-out “where the heck did that come from” errors like “Caigo” in the first example under Large Language Models above; on another occasion, it might.
But the quibbles are not the point. The point is what it can do.
What logic is implicit in the wall of numbers that lets this happen? We don’t know, and ChatGPT’s builders don’t know. Nobody knows.
Well then, can we just assume the wall contains — somehow — the same kinds of structures that we’d use if we wrote this program by hand? No, because we don’t have a clue how to write a program like this by hand. Not the faintest inkling.
So I guess we’ve proved there is a secret sauce? Yes.
And we’ve found it, in the wall of numbers? Yes.
But we have no idea what it is or how it works? Correct.
Is that the big caveat you’ve mentioned a couple of times? Bingo.
Training has packed meaning into the neurons in the network and the numbers on the wall, as well as larger structures connecting them such as what have been called circuits. This is the secret sauce. But we know only that it’s there. We have virtually zero access to it, and virtually zero detail-level understanding of how it does what it does.
Circling back
Let’s conclude by returning to the claims from various parties, both AI boosters and skeptics — though again, I think a minority of both — that what we’ve been discussing is just software.
As a well-informed mortal, you’re now equipped to judge for yourself. What do you think?
Here’s what I think: the claim is ludicrous. As we’ve seen, nothing in the built LLM initially contains anything that’s actually about anything. We didn’t grace it with any code, any programming instructions, to tell it how to behave.
We don’t need to join the ongoing debate about whether the LLM merits the term intelligent; it’s enough to know that it’s doing something unprecedented, astonishing, seemingly magical, something we didn’t create and wouldn’t know how to create, something that is encoded — somehow — within its wall of learned weights.
The LLM learns what it knows from us, but in a way utterly unlike conventional programming. It learns our languages and much else about our world by absorbing what others have said. The only other thing that can do that is a child.
We certainly don’t know how to reason about the LLM’s learned “program” in the ways we would reason about legacy software, to anticipate what it might do for us or where it might go wrong. In every way that matters, we’re on entirely new ground, and we need a new playbook. This is not something to be left to the Marc Andreessens and Parmy Olsons of the world. We all have a stake, we all need a voice, and we all deserve the chance to consider for ourselves this profound wonder coming into being right in front of us.
If you want more to read…
With a hat tip to my friend Robin Simons, who passed it along, here’s a cool article (unlocked link) from The New York Times’s TheUpshot newsletter about what it looks like as a tiny LLM progresses through the stages of training.
This story in Quanta magazine talks about a project some scientists took on to illustrate just how simple an artificial neuron is, compared to a biological one, by figuring out how big an artificial neural network you’d have to make to simulate a single biological neuron. Spoiler alert: pretty big!
If you’re up for a little more challenge — okay, I admit it, considerably more challenge, but it’s skimmable — this paper by Samuel R. Bowman is a fascinating survey of important high-level things we’re realizing about how LLMs work and what they do.
If you want to know where LLMs came from…
Although LLMs came on very fast, even by technology standards, they had a long line of predecessors, and they represent the work of a large number of incredibly gifted and dedicated people. Here’s a whirlwind tour of some of the crucial milestones. These are excerpted from Wikipedia’s articles on Transformers and Large Language Models. (Transformers are the particular style of neural network architecture used in most current LLMs.)
- 2016: Google updates its Translate product to use a neural network engine. This also introduces the idea of attention, which, roughly speaking, is a way to use the context of an entire input sequence at the same time. That’s crucial for LLMs!
- 2017: Google (mostly) researchers introduce the Transformer model via a groundbreaking paper: Attention Is All You Need. This ignites the current explosion in work on what we now call LLMs.
- 2018: OpenAI introduces GPT-1, and Google releases BERT.
- 2019: OpenAI introduces GPT-2.
- 2020: OpenAI introduces GPT-3. This was the model that caught the attention of a wide range of non-specialists (eventually including me fwiw!)
- 2021: Multiple new players introduce models, including an open-source one from EleutherAI, and a non-US (Chinese) one from Baidu.
- 2022: Google introduces LaMDA (the model that was famously claimed to be sentient by Blake Lemoine) and PaLM, and, oh yeah, OpenAI releases ChatGPT.
- 2023: New releases continue at a rapid pace from an expanding group of players. Introductions include LLaMA from Meta, GPT-4 from OpenAI, Grok-1 from xAI (aka Elon Musk), and Gemini from Google, among many others.
If you want to know what I glossed over in the technical sections…
As I mentioned in the main text, I took some liberties with technical details, though I believe in a way that didn’t compromise the validity of the story. Here’s a list of the main ones I’m aware of. The details are probably boring and unnecessary, but you might be interested in quickly glancing over the list just to see what kinds of things I’m talking about:
- LLMs don’t typically work with words, exactly, but with tokens. Lots of times tokens are words, but pretty often they’re parts of words, punctuation marks, etc.
- The LLM doesn’t just return a predicted next token. It gives the probability of occurrence for every token in its vocabulary. Then the application that’s using the LLM either takes the token with the highest probability, or rolls a virtual pair of dice to make a selection that takes the probabilities into account, but also introduces some randomness.
- What LLMs really share with applications (eg ChatGPT) is a fixed-length context window. They don’t necessarily set token probabilities just at the first unfilled slot, but everywhere indicated by the app; it can even be in the middle of existing text. That said, what the main story described, where the app only looks at one next token at a time, is the main case.
- I didn’t mention that neurons take a bias parameter that’s not associated with an incoming connection.
- The attention mechanism used by transformers (and therefore by most LLMs) adds some complexity to the simple picture of uniform layers in the neural network. It’s a bit too much to explain here, but doesn’t meaningfully affect the overall story.
- When you interact with an application program, especially a chatbot such as ChatGPT, there are a few things going on between you and the base LLM that muddy the simple text completion picture described in this post. Among other things, the model itself may get additional fine-tuning for use with a particular application, and/or prompt text specified by the manufacturer may get mixed in with your prompts and constrain the model’s responses. (Such things are why the first example under Large Language Models used GPT-4 directly rather than ChatGPT.)
This article originally appeared in AI for Mortals under a Creative Commons BY-ND license. Some rights reserved.